Human can leverage prior experience and learn novel tasks from a handful of demonstrations. In contrast to offline meta-reinforcement learning, which aims to achieve quick adaptation through better algorithm design, we investigate the effect of architecture inductive bias on the few-shot learning capability. We propose the Prompt-based Decision Transformer (Prompt-DT), which leverages the sequential modeling ability of Transformer architecture and the prompt framework to achieve few-shot adaptation in offline RL. We design the trajectory prompt, which contains segments of the few-shot demonstrations, and encodes task-specific information to guide policy generation. Our experiments in several Mujoco control tasks show that Prompt-DT is a strong few-shot learner without any extra finetuning on unseen target tasks. Prompt-DT outperforms its variants and strong meta offline RL baselines by a large margin with a trajectory prompt containing only a few timesteps. Prompt-DT is also robust to prompt length changes and can generalize to out-of-distribution (OOD) environments.
Prompt-DT Architecture
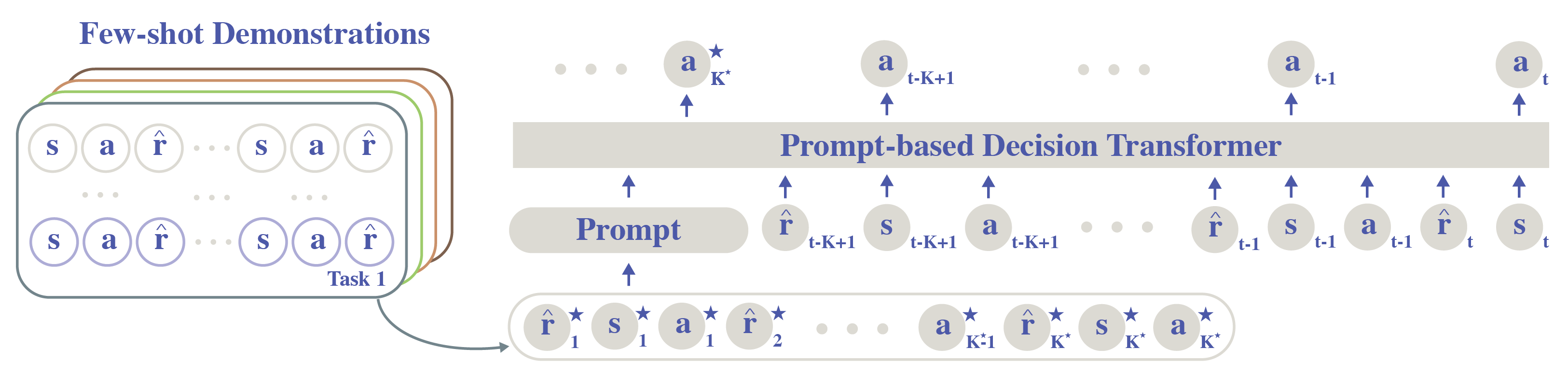
Our Prompt-DT architecture is built on Decision Transformer [Chen et al., 2021] and solves the offline few-shot RL problem through the lens of a prompt-augmented sequence-modeling problem. The proposed trajectory prompt allows minimal architecture change to the Decision Transformer for generalization. For each task at training and testing time, Prompt-DT takes as input both the trajectory prompt obtained from expert demonstrations and the most recent context history. The data pair at each timestep is a 3-tuple (including state, action, and reward-to-go). Prompt-DT autoregressively outputs actions at heads corresponding to state tokens in the input sequence.
Few-Shot Policy Generalization to In-distribution Tasks
We evaluate Prompt-DT in five environments that are widely used in offline meta-RL literature, including Cheetah-dir, Cheetah-vel, Ant-dir, Dial, and Metaworld-reach-v2. We compare Prompt-DT with Prompt-based Behavior Cloning (Prompt-MT-BC) to ablate the effect of reward-to-go tokens, Multi-task Offline RL (MT-ORL) to ablate the efficiency of our proposed trajectory prompts, Multi-task Behavior Cloning (MT-BC-Finetune), and Meta-Actor Critic with Advantage Weighting (MACAW) [Mitchell et al., 2021]. We find that Prompt-DT achieves high episodic accumulated rewards in never-before-seen tasks across environments by matching the task-specific information stored in a short trajectory prompt.
Cheetah-dir

Prompt-DT
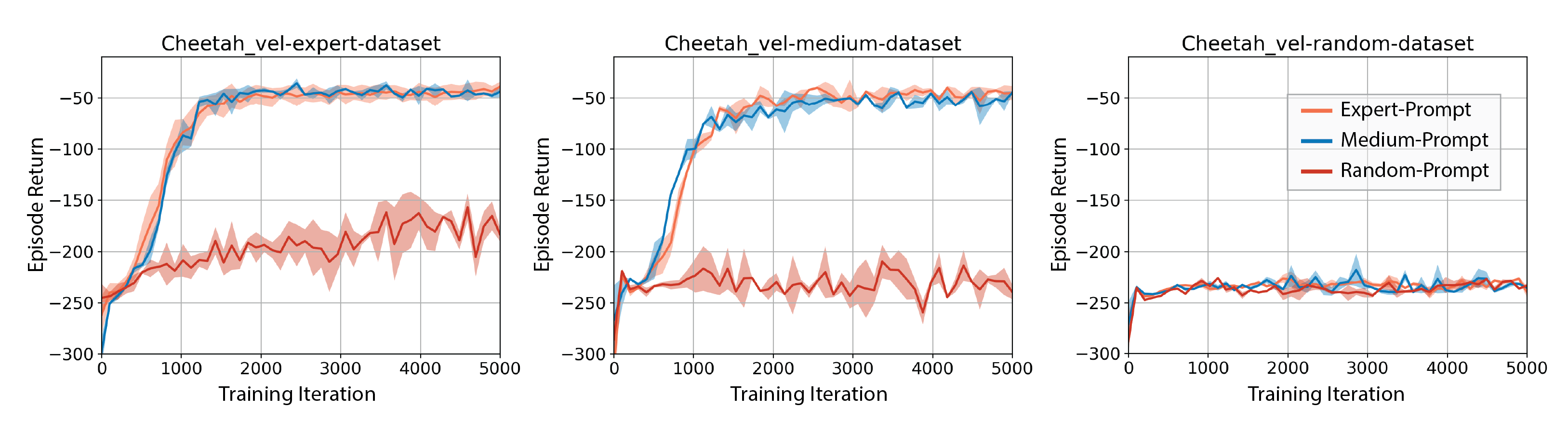
Cheetah-vel

Prompt-DT
Meta-World pick-place-v2
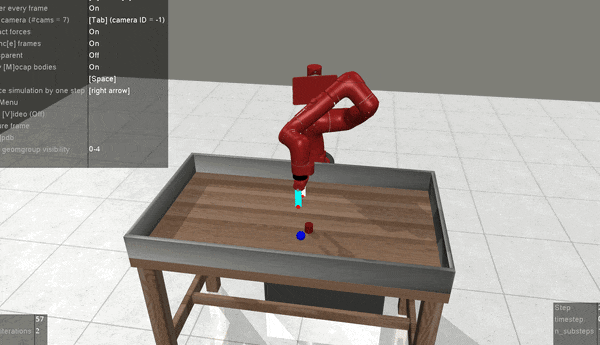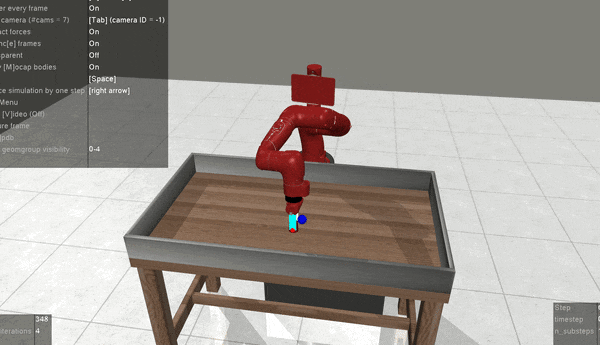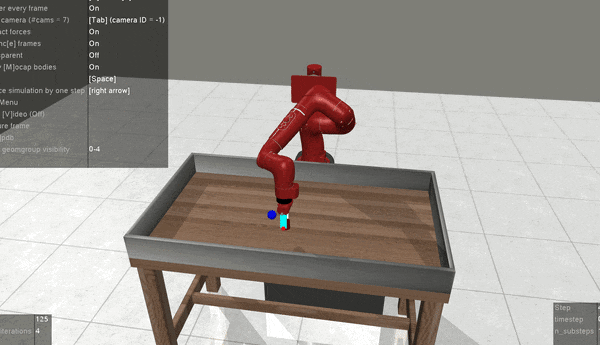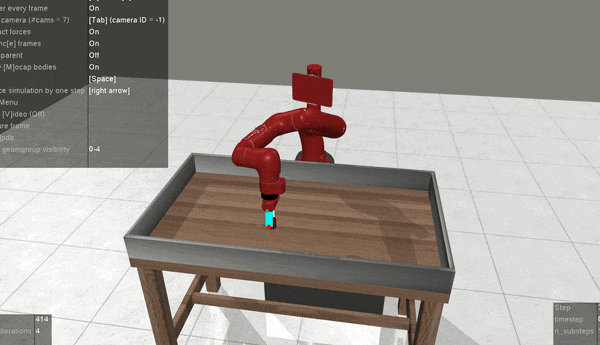
Prompt-DT

MT-ORL

MT-ORL
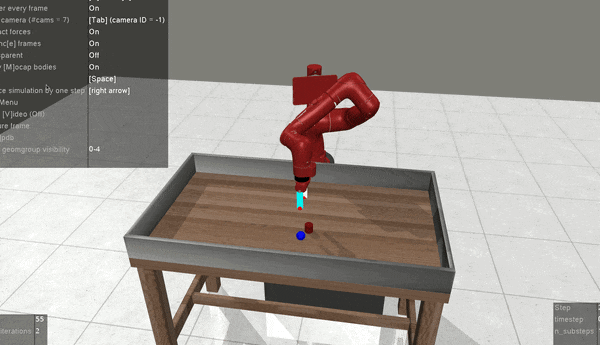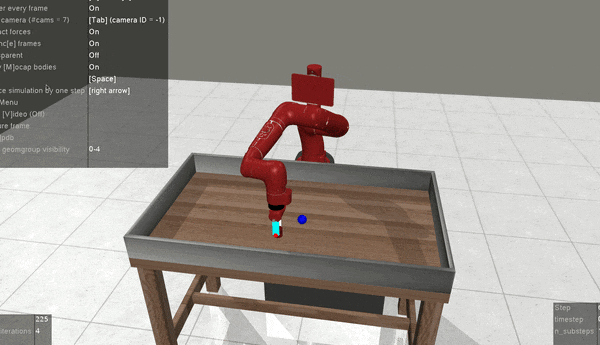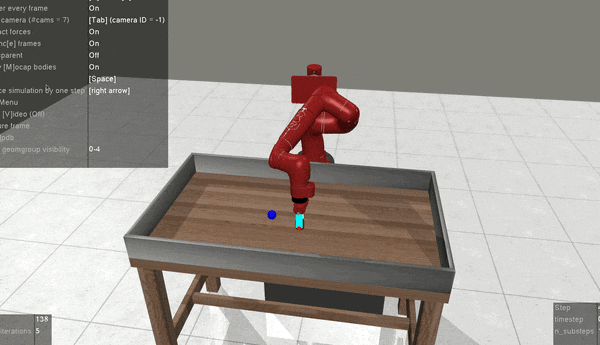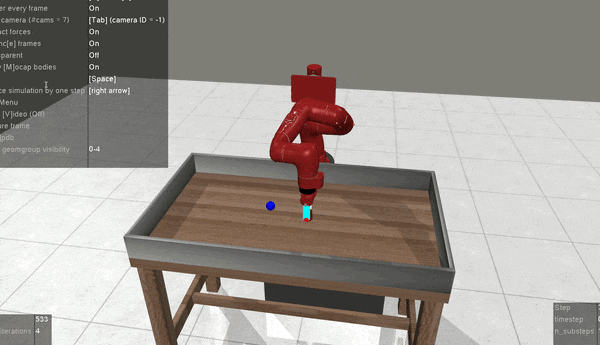
MT-ORL
Few-Shot Policy Generalization to Out-of-distribution Tasks
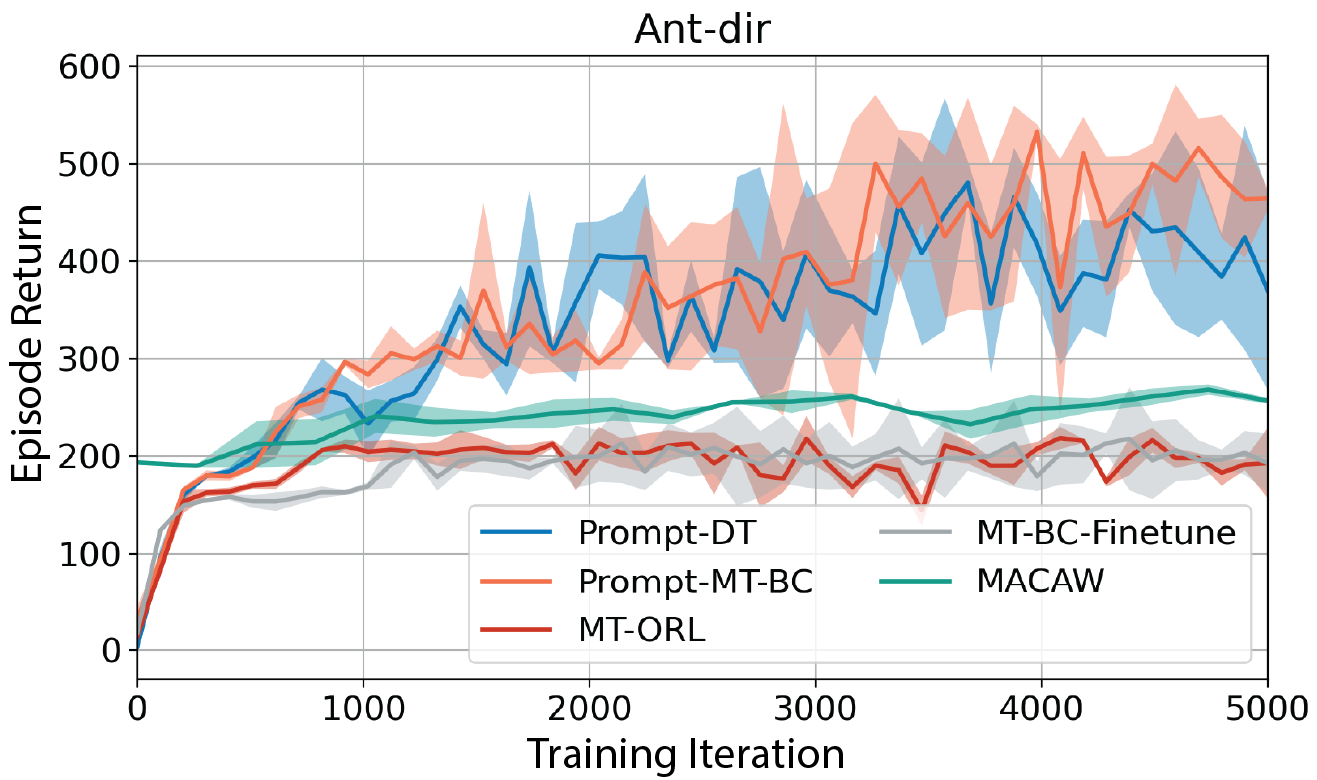
We desire to test whether trajectory prompts enable the extrapolation ability when handling tasks with goals out of the training ranges. We sample 8 training tasks in Ant-dir and 3 testing tasks, two of which have indexes smaller than the minimum task index and one larger than the maximum. The task index is proportional to the desired direction angle. We find that Prompt-DT still performs better than baselines with no prompt augmentations.
Sensitivity to Prompt Quantity and Quality
In practice, there may exist a limited amount of high-quality demonstrations for each test task, or the demonstrations may contain trajectories with heterogeneous quality. Our experiments show that, with trajectory prompt sampled from expert demonstrations and expert training dataset, Prompt-DT is not sensitive to the prompt quantity and can successfully extract task-specific information even with prompts containing only a few timesteps. We conduct an ablation study in Cheetah-vel for prompt quality. We find that Prompt-DT could adjust its generated actions according to the given trajectory prompt when training with expert data or medium data. However, when training with random data, only feeding Prompt-DT expert or medium trajectory prompts does not help improve the generalization ability.